We attempted to fit four conceptually different models to the dataset: multilayer perceptron, k-nearest-neighbor (IBk), linear regression, and decision tree of linear regression (M5P). Assessing the output, linear regression is clearly not a suitable model. We believe that the reason is that if the linear regression partition and encode the Genre variable as 10 different dummy variables, we need to omit one indicator variable to have the correct degrees of freedom. We are unsure if this simple linear regression model is robust for dummy variables. Multilayer perceptron and k-nearest-neighbor had similar performance. It is expected that movies should be clusters grouped by box office. Intuitively, there is positive relationships between Facebook likes, star power, IMDB ratings and gross box office – the more popular they are, the more box office they are likely to have. Multilayer perceptron could certainly model this relationship, with the added benefit over linear regression with nodes that indicate Genre. The decision tree of linear regression performed the best, yielding 30% relative absolute error (given that Gross is relatively large, we expect a larger percent error). Our result verifies the widely accepted Machine Learning opinion that ensemble models tend to outperform their individual components.

|
Nearest NeighborCorrelation coefficient
0.9051 Mean absolute error 42578050.2019 Root mean squared error 83538398.7734 Relative absolute error 34.761 % Root relative squared error 43.2274 % Total Number of Instances 1107 |
|
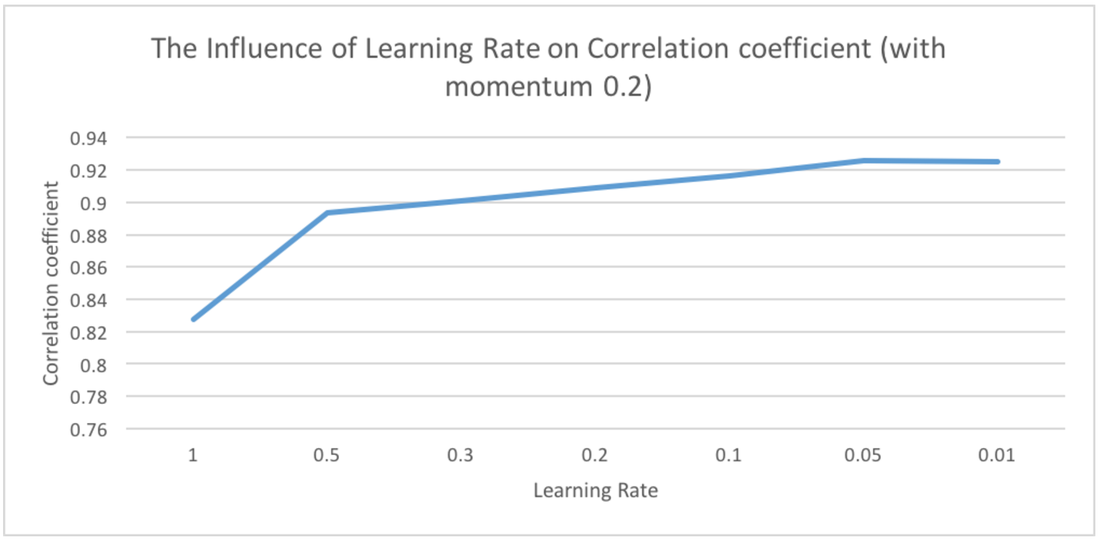
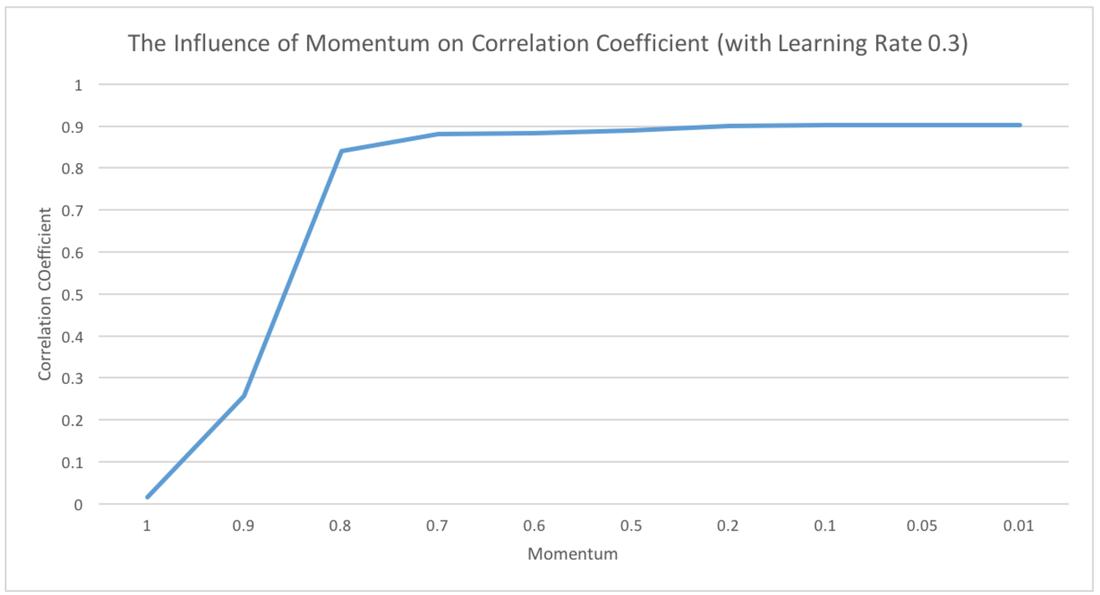
Multilayer PerceptronCorrelation coefficient
0.9246 Mean absolute error 44535328.4798 Root mean squared error 73799243.7654 Relative absolute error 36.3589 % Root relative squared error 38.1878 % Total Number of Instances 1107 |