The Problem
Our task is to predict the box office earnings of a film based on social media data, online ratings, and details about the film, including the genre, director, and actors. This task is important because it could help production companies predict the box office outcomes of their new releases, which would allow them to cater movies to their audiences and produce more profitable movies. During the soft openings of films, before they are released to the public but after they have been seen by critics and reviewers, based on the critic reviews and social media buzz, studios will have the power to control their earnings more precisely.
The Solution
To investigate the determining factors behind film box office results, we compiled a large data set of recent films, along with social media information and past box office earnings. Using an M5P learning model, a combination of the traditional decision tree and linear regression functions, we were able to minimize our average error, testing across our master data set. After testing several different values for minimum number of instances to allow at a leaf node, we found that our error was lowest with a value of 4. In addition to the M5P, we also tested multilayer perceptron, nearest neighbor, and linear regression models.
Testing and Training
To begin predicting box office outcome, we compiled a large data set (about 1200 items) made up of every film released between the years 2010 and 2016. For each film, we have a number of details, including:
To collect the basic information for each film, including the title, director, genre, and box office earnings, we used Wikipedia's API.
To test and train our model, we used 10-fold cross validation on each model. This allowed us to split our large data set up and use it for both training and testing our results. Because our data set contains information on films up to present day, this method allowed us to easily partition our data and evaluate the accuracy of each method on current films.
To measure the accuracy of each model, we looked at the mean absolute error, and the relative absolute error.
- Genre: The film's genre, narrowed down to ten broad categories.
- IMDB Rating: The average rating between 1 and 10 given to the film.
- Facebook Likes: The number of "likes" on either the official Facebook page for the film, or the most prominent community fan page.
- Star Power: Each individual actor's "star power" was calculated by averaging the box office earnings of each film that he or she has starred in since 2010. The star power for each film was calculated by averaging the star power of all of its top billed actors. We found these numbers by training over our own data set, using Python.
- Box Office Earnings: The amount of money that the film earned internationally while in theaters.
To collect the basic information for each film, including the title, director, genre, and box office earnings, we used Wikipedia's API.
To test and train our model, we used 10-fold cross validation on each model. This allowed us to split our large data set up and use it for both training and testing our results. Because our data set contains information on films up to present day, this method allowed us to easily partition our data and evaluate the accuracy of each method on current films.
To measure the accuracy of each model, we looked at the mean absolute error, and the relative absolute error.
The Results
Using the M5P model, we were able to train and test on our data set with about 30% relative absolute error, with the mean absolute error of about $37 million. Although this is the lowest error rate among our tested algorithms, there is still much room for improvement. Among our four attributes, we found that star power was the most important, and provided the learner with the most information. Facebook likes also had a significant impact, followed by IMDB ratings, and genre.
In order for us to improve our results and reduce errors, there are several steps we could take in the future. The main two strategies would be to expand our data set to earlier years, and to add more numeric attributes to our data set. In terms of social media, bringing in more platforms, such as Twitter and Instagram, could provide us with more insight into the buzz around upcoming films. Additionally, it could be interesting to look at movie budgets, release dates, and production studio statistics.
In order for us to improve our results and reduce errors, there are several steps we could take in the future. The main two strategies would be to expand our data set to earlier years, and to add more numeric attributes to our data set. In terms of social media, bringing in more platforms, such as Twitter and Instagram, could provide us with more insight into the buzz around upcoming films. Additionally, it could be interesting to look at movie budgets, release dates, and production studio statistics.
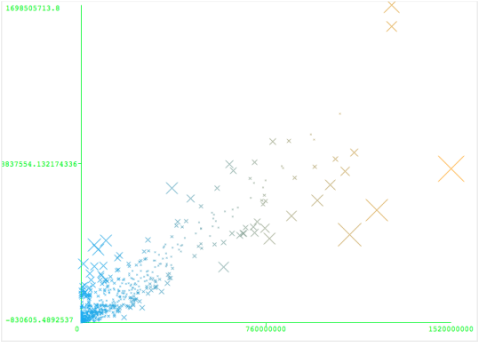
The relationship between actual box office results (X) and our predicted results (Y) for each instance. Error is represented by the size of each mark.
|

A visualization of our final M5P tree.
|
